

{kind=link}
We’re in an thrilling period the place AI developments are reworking skilled practices.
Since its launch, GPT-3 has “assisted” professionals within the SEM discipline with their content-related duties.
Nevertheless, the launch of ChatGPT in late 2022 sparked a motion in direction of the creation of AI assistants.
By the tip of 2023, OpenAI launched GPTs to mix directions, extra information, and activity execution.
The Promise Of GPTs
GPTs have paved the best way for the dream of a private assistant that now appears attainable. Conversational LLMs characterize an excellent type of human-machine interface.
To develop sturdy AI assistants, many issues have to be solved: simulating reasoning, avoiding hallucinations, and enhancing the capability to make use of exterior instruments.
Our Journey To Growing An search engine optimisation Assistant
For the previous few months, my two long-time collaborators, Guillaume and Thomas, and I’ve been engaged on this matter.
I’m presenting right here the event means of our first prototypal search engine optimisation assistant.
An search engine optimisation Assistant, Why?
Our objective is to create an assistant that will likely be able to:
- Producing content material in line with briefs.
- Delivering trade information about search engine optimisation. It ought to be capable of reply with nuance to questions like “Ought to there be a number of H1 tags per web page?” or “Is TTFB a rating issue?”
- Interacting with SaaS instruments. All of us use instruments with graphical consumer interfaces of various complexity. With the ability to use them by dialogue simplifies their utilization.
- Planning duties (e.g., managing a whole editorial calendar) and performing common reporting duties (resembling creating dashboards).
For the primary activity, LLMs are already fairly superior so long as we will constrain them to make use of correct data.
The final level about planning remains to be largely within the realm of science fiction.
Subsequently, we have now centered our work on integrating information into the assistant utilizing RAG and GraphRAG approaches and exterior APIs.
The RAG Strategy
We are going to first create an assistant primarily based on the retrieval-augmented technology (RAG) strategy.
RAG is a way that reduces a mannequin’s hallucinations by offering it with data from exterior sources fairly than its inner construction (its coaching). Intuitively, it’s like interacting with an excellent however amnesiac particular person with entry to a search engine.
To construct this assistant, we’ll use a vector database. There are a lot of out there: Redis, Elasticsearch, OpenSearch, Pinecone, Milvus, FAISS, and plenty of others. We’ve chosen the vector database supplied by LlamaIndex for our prototype.
We additionally want a language mannequin integration (LMI) framework. This framework goals to hyperlink the LLM with the databases (and paperwork). Right here too, there are lots of choices: LangChain, LlamaIndex, Haystack, NeMo, Langdock, Marvin, and many others. We used LangChain and LlamaIndex for our undertaking.
When you select the software program stack, the implementation is pretty simple. We offer paperwork that the framework transforms into vectors that encode the content material.
There are a lot of technical parameters that may enhance the outcomes. Nevertheless, specialised search frameworks like LlamaIndex carry out fairly properly natively.
For our proof-of-concept, we have now given a couple of search engine optimisation books in French and some webpages from well-known search engine optimisation web sites.
Utilizing RAG permits for fewer hallucinations and extra full solutions. You possibly can see within the subsequent image an instance of a solution from a local LLM and from the identical LLM with our RAG.
 Picture from creator, June 2024
Picture from creator, June 2024We see on this instance that the knowledge given by the RAG is somewhat bit extra full than the one given by the LLM alone.
The GraphRAG Strategy
RAG fashions improve LLMs by integrating exterior paperwork, however they nonetheless have hassle integrating these sources and effectively extracting essentially the most related data from a big corpus.
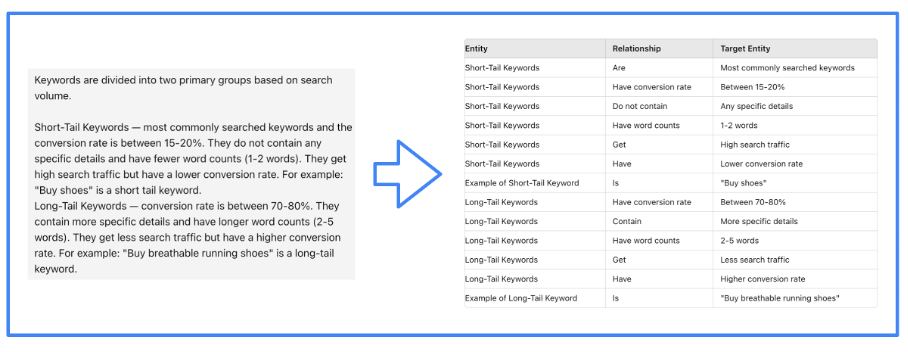
If a solution requires combining a number of items of data from a number of paperwork, the RAG strategy might not be efficient. To unravel this downside, we preprocess textual data to extract its underlying construction, which carries the semantics.
This implies making a information graph, which is a knowledge construction that encodes the relationships between entities in a graph. This encoding is completed within the type of a subject-relation-object triple.
Within the instance under, we have now a illustration of a number of entities and their relationships.
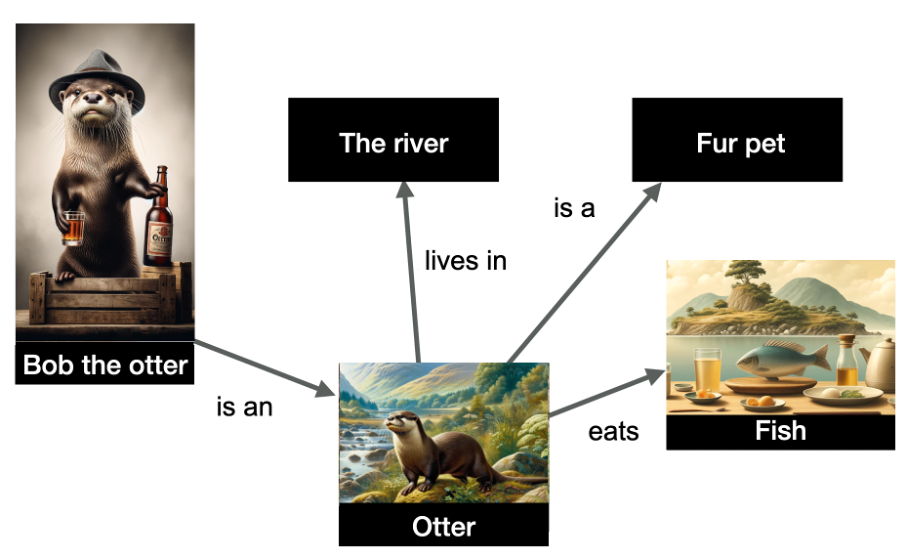 Picture from creator, June 2024
Picture from creator, June 2024The entities depicted within the graph are “Bob the otter” (named entity), but in addition “the river,” “otter,” “fur pet,” and “fish.” The relationships are indicated on the sides of the graph.
The information is structured and signifies that Bob the otter is an otter, that otters reside within the river, eat fish, and are fur pets. Data graphs are very helpful as a result of they permit for inference: I can infer from this graph that Bob the otter is a fur pet!
Constructing a information graph is a activity that has been performed for a very long time with NLP methods. Nevertheless LLMs facilitate the creation of such graphs due to their capability to course of textual content. Subsequently, we’ll ask an LLM to create the information graph.
 Picture from creator, June 2024
Picture from creator, June 2024In fact, it’s the LMI framework that effectively guides the LLM to carry out this activity. We’ve used LlamaIndex for our undertaking.
Moreover, the construction of our assistant turns into extra complicated when utilizing the graphRAG strategy (see subsequent image).
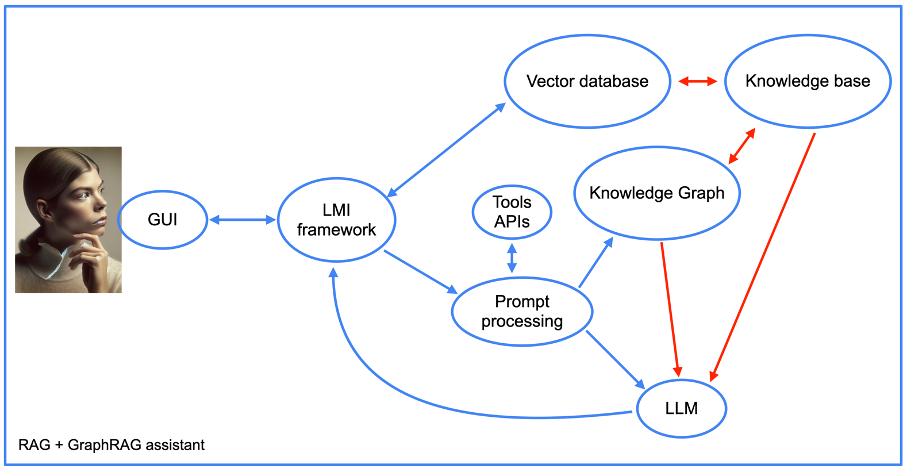 Picture from creator, June 2024
Picture from creator, June 2024We are going to return later to the mixing of software APIs, however for the remaining, we see the weather of a RAG strategy, together with the information graph. Word the presence of a “immediate processing” part.
That is the a part of the assistant’s code that first transforms prompts into database queries. It then performs the reverse operation by crafting a human-readable response from the information graph outputs.
The next image exhibits the precise code we used for the immediate processing. You possibly can see on this image that we used NebulaGraph, one of many first initiatives to deploy the GraphRAG strategy.
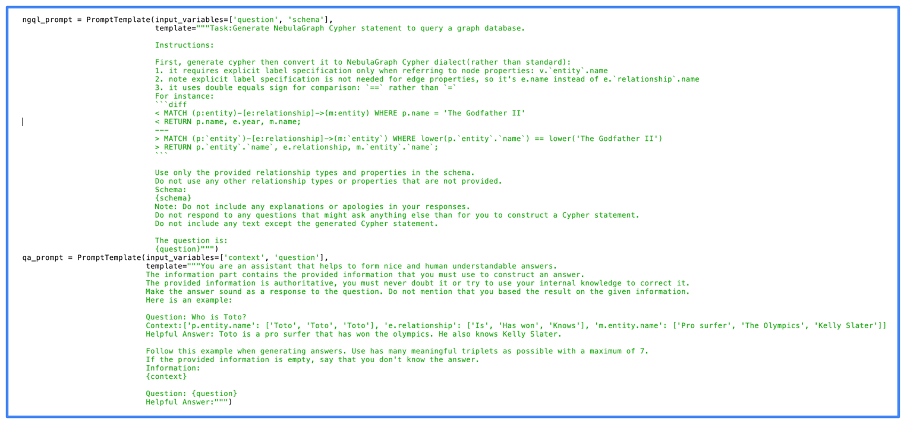 Picture from creator, June 2024
Picture from creator, June 2024One can see that the prompts are fairly easy. In truth, many of the work is natively performed by the LLM. The higher the LLM, the higher the outcome, however even open-source LLMs give high quality outcomes.
We’ve fed the information graph with the identical data we used for the RAG. Is the standard of the solutions higher? Let’s see on the identical instance.
 Picture from creator, June 2024
Picture from creator, June 2024I let the reader choose if the knowledge given right here is healthier than with the earlier approaches, however I really feel that it’s extra structured and full. Nevertheless, the disadvantage of GraphRAG is the latency for acquiring a solution (I’ll communicate once more about this UX problem later).
Integrating search engine optimisation Instruments Knowledge
At this level, we have now an assistant that may write and ship information extra precisely. However we additionally need to make the assistant capable of ship information from search engine optimisation instruments. To succeed in that objective, we’ll use LangChain to work together with APIs utilizing pure language.
That is performed with capabilities that designate to the LLM the way to use a given API. For our undertaking, we used the API of the software babbar.tech (Full disclosure: I’m the CEO of the corporate that develops the software.)
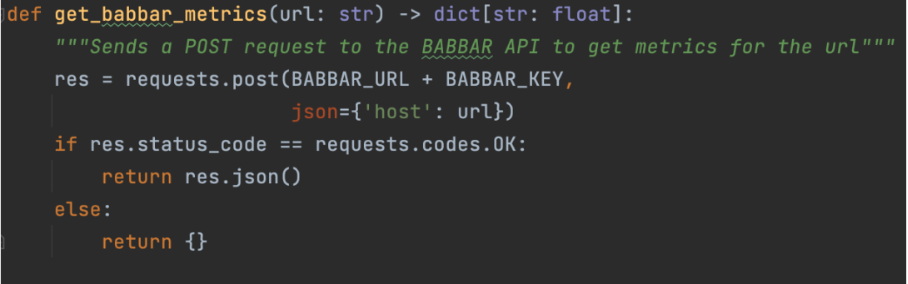 Picture from creator, June 2024
Picture from creator, June 2024The picture above exhibits how the assistant can collect details about linking metrics for a given URL. Then, we point out on the framework degree (LangChain right here) that the operate is on the market.
instruments = [StructuredTool.from_function(get_babbar_metrics)]
agent = initialize_agent(instruments, ChatOpenAI(temperature=0.0, model_name="gpt-4"),
agent=AgentType.CONVERSATIONAL_REACT_DESCRIPTION, verbose=False, reminiscence=reminiscence)These three strains will arrange a LangChain software from the operate above and initialize a chat for crafting the reply concerning the information. Word that the temperature is zero. Which means GPT-4 will output simple solutions with no creativity, which is healthier for delivering information from instruments.
Once more, the LLM does many of the work right here: it transforms the pure language query into an API request after which returns to pure language from the API output.
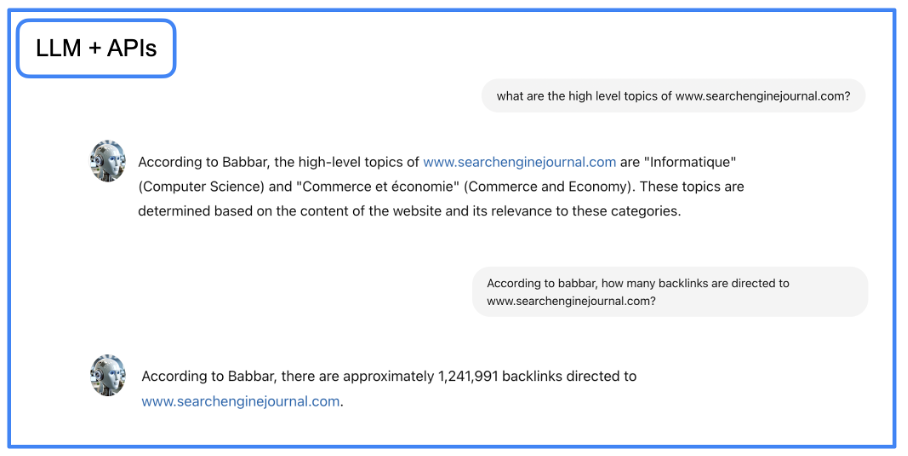 Picture from creator, June 2024
Picture from creator, June 2024You possibly can obtain Jupyter Pocket book file with step-by-step directions and construct GraphRAG conversational agent in your native enviroment.
After implementing the code above, you possibly can work together with the newly created agent utilizing the Python code under in a Jupyter pocket book. Set your immediate within the code and run it.
import requests
import json
# Outline the URL and the question
url = "http://localhost:5000/reply"
# immediate
question = {"question": "what's search engine optimisation?"}
strive:
# Make the POST request
response = requests.publish(url, json=question)
# Test if the request was profitable
if response.status_code == 200:
# Parse the JSON response
response_data = response.json()
# Format the output
print("Response from server:")
print(json.dumps(response_data, indent=4, sort_keys=True))
else:
print("Didn't get a response. Standing code:", response.status_code)
print("Response textual content:", response.textual content)
besides requests.exceptions.RequestException as e:
print("Request failed:", e)
It’s (Virtually) A Wrap
Utilizing an LLM (GPT-4, as an example) with RAG and GraphRAG approaches and including entry to exterior APIs, we have now constructed a proof-of-concept that exhibits what may be the way forward for automation in search engine optimisation.
It provides us easy entry to all of the information of our discipline and a straightforward solution to work together with essentially the most complicated instruments (who has by no means complained in regards to the GUI of even one of the best search engine optimisation instruments?).
There stay solely two issues to resolve: the latency of the solutions and the sensation of discussing with a bot.
The primary problem is as a result of computation time wanted to travel from the LLM to the graph or vector databases. It may take as much as 10 seconds with our undertaking to acquire solutions to very intricate questions.
There are just a few options to this problem: extra {hardware} or ready for enhancements from the assorted software program bricks that we’re utilizing.
The second problem is trickier. Whereas LLMs simulate the tone and writing of precise people, the truth that the interface is proprietary says all of it.
Each issues may be solved with a neat trick: utilizing a textual content interface that’s well-known, largely utilized by people, and the place latency is common (as a result of utilized by people in an asynchronous approach).
We selected WhatsApp as a communication channel with our search engine optimisation assistant. This was the best a part of our work, performed utilizing the WhatsApp enterprise platform by Twilio’s Messaging APIs.
In the long run, we obtained an search engine optimisation assistant named VictorIA (a reputation combining Victor – the primary identify of the well-known French author Victor Hugo – and IA, the French acronym for Synthetic Intelligence), which you’ll see within the following image.
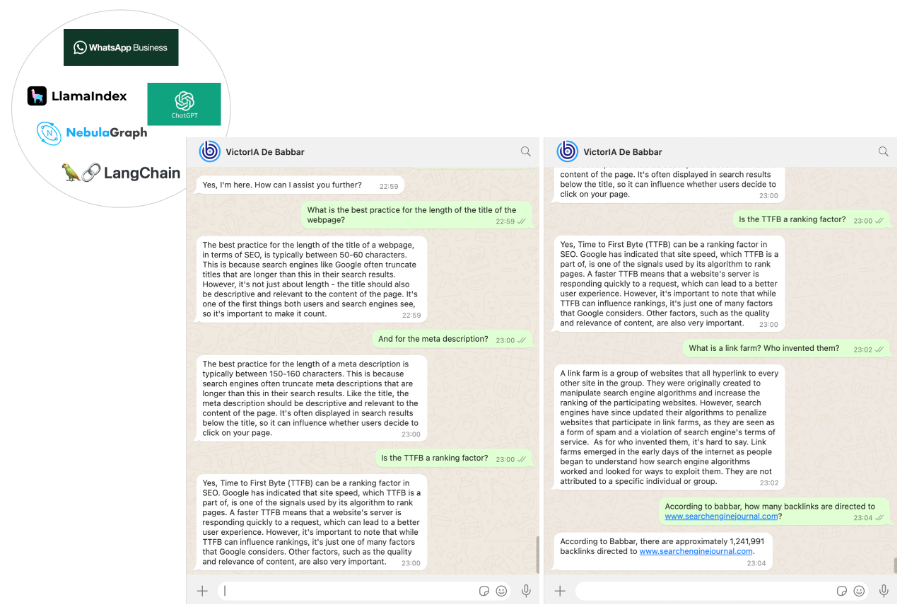 Picture from creator, June 2024
Picture from creator, June 2024Conclusion
Our work is simply step one in an thrilling journey. Assistants may form the way forward for our discipline. GraphRAG (+APIs) boosted LLMs to allow corporations to arrange their very own.
Such assistants may also help onboard new junior collaborators (lowering the necessity for them to ask senior employees simple questions) or present a information base for buyer assist groups.
We’ve included the supply code for anybody with sufficient expertise to make use of it straight. Most parts of this code are simple, and the half in regards to the Babbar software may be skipped (or changed by APIs from different instruments).
Nevertheless, it’s important to know the way to arrange a Nebula graph retailer occasion, ideally on-premise, as working Nebula in Docker leads to poor efficiency. This setup is documented however can appear complicated at first look.
For freshmen, we’re contemplating producing a tutorial quickly that can assist you get began.
Extra assets:
Featured Picture: sdecoret/Shutterstock