

{kind=link}
Crawling is crucial for each web site, massive and small alike.
In case your content material isn’t being crawled, you don’t have any likelihood to realize visibility on Google surfaces.
Let’s discuss find out how to optimize crawling to offer your content material the publicity it deserves.
What Is Crawling In Website positioning
Within the context of Website positioning, crawling is the method by which search engine bots (also called net crawlers or spiders) systematically uncover content material on a web site.
This can be textual content, photos, movies, or different file varieties which might be accessible to bots. Whatever the format, content material is solely discovered by way of hyperlinks.
How Net Crawling Works
An online crawler works by discovering URLs and downloading the web page content material.
Throughout this course of, they could go the content material over to the search engine index and can extract hyperlinks to different net pages.
These discovered hyperlinks will fall into totally different categorizations:
- New URLs which might be unknown to the search engine.
- Identified URLs that give no steerage on crawling shall be periodically revisited to find out whether or not any modifications have been made to the web page’s content material, and thus the search engine index wants updating.
- Identified URLs which were up to date and provides clear steerage. They need to be recrawled and reindexed, akin to through an XML sitemap final mod date time stamp.
- Identified URLs that haven’t been up to date and provides clear steerage. They shouldn’t be recrawled or reindexed, akin to a HTTP 304 Not Modified response header.
- Inaccessible URLs that may not or shouldn’t be adopted, for instance, these behind a log-in type or hyperlinks blocked by a “nofollow” robots tag.
- Disallowed URLs that search engine bots is not going to crawl, for instance, these blocked by the robots.txt file.
All allowed URLs shall be added to a listing of pages to be visited sooner or later, often known as the crawl queue.
Nevertheless, they are going to be given totally different ranges of precedence.
That is dependent not solely upon the hyperlink categorization however a bunch of different elements that decide the relative significance of every web page within the eyes of every search engine.
Hottest serps have their very own bots that use particular algorithms to find out what they crawl and when. This implies not all crawl the identical.
Googlebot behaves in a different way from Bingbot, DuckDuckBot, Yandex Bot, or Yahoo Slurp.
Why It’s Essential That Your Web site Can Be Crawled
If a web page on a web site isn’t crawled, it is not going to be ranked within the search outcomes, as it’s extremely unlikely to be listed.
However the the reason why crawling is crucial go a lot deeper.
Speedy crawling is crucial for time-limited content material.
Typically, if it isn’t crawled and given visibility rapidly, it turns into irrelevant to customers.
For instance, audiences is not going to be engaged by final week’s breaking information, an occasion that has handed, or a product that’s now bought out.
However even should you don’t work in an trade the place time to market is crucial, speedy crawling is at all times useful.
If you refresh an article or launch a major on-page Website positioning change, the sooner Googlebot crawls it, the sooner you’ll profit from the optimization – or see your mistake and be capable of revert.
You may’t fail quick if Googlebot is crawling slowly.
Consider crawling because the cornerstone of Website positioning; your natural visibility is totally dependent upon it being finished effectively in your web site.
Measuring Crawling: Crawl Funds Vs. Crawl Efficacy
Opposite to in style opinion, Google doesn’t purpose to crawl and index all content material of all web sites throughout the web.
Crawling of a web page isn’t assured. In reality, most websites have a considerable portion of pages which have by no means been crawled by Googlebot.
For those who see the exclusion “Found – at the moment not listed” within the Google Search Console web page indexing report, this subject is impacting you.
But when you don’t see this exclusion, it doesn’t essentially imply you don’t have any crawling points.
There’s a frequent false impression about what metrics are significant when measuring crawling.
Crawl funds fallacy
Website positioning professionals usually look to crawl funds, which refers back to the variety of URLs that Googlebot can and desires to crawl inside a selected time-frame for a selected web site.
This idea pushes for maximization of crawling. That is additional bolstered by Google Search Console’s crawl standing report exhibiting the entire variety of crawl requests.
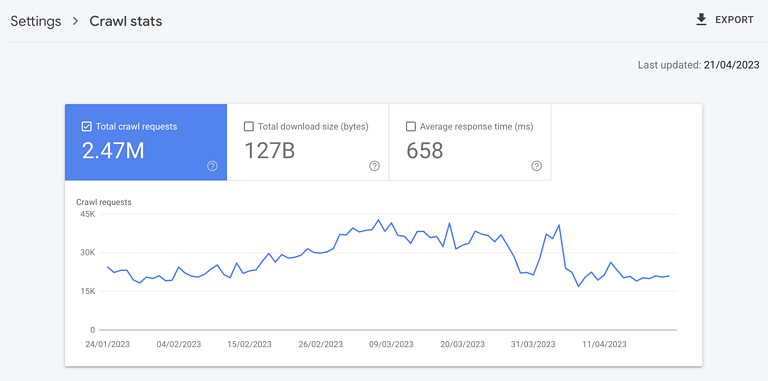
However the concept that extra crawling is inherently higher is totally misguided. The whole variety of crawls is nothing however an arrogance metric.
Attractive 10 occasions the variety of crawls per day doesn’t essentially correlate towards sooner (re)indexing of content material you care about. All it correlates with is placing extra load in your servers, costing you more cash.
The main focus ought to by no means be on rising the entire quantity of crawling, however slightly on high quality crawling that ends in Website positioning worth.
Crawl Efficacy Worth
High quality crawling means lowering the time between publishing or making important updates to an Website positioning-relevant web page and the following go to by Googlebot. This delay is the crawl efficacy.
To find out the crawl efficacy, the beneficial method is to extract the created or up to date datetime worth from the database and examine it to the timestamp of the following Googlebot crawl of the URL within the server log information.
If this isn’t attainable, you may think about calculating it utilizing the lastmod date within the XML sitemaps and periodically question the related URLs with the Search Console URL Inspection API till it returns a final crawl standing.
By quantifying the time delay between publishing and crawling, you may measure the true affect of crawl optimizations with a metric that issues.
As crawl efficacy decreases, the sooner new or up to date Website positioning-relevant content material shall be proven to your viewers on Google surfaces.
In case your web site’s crawl efficacy rating reveals Googlebot is taking too lengthy to go to content material that issues, what are you able to do to optimize crawling?
Search Engine Assist For Crawling
There was a whole lot of discuss in the previous couple of years about how serps and their companions are centered on enhancing crawling.
In any case, it’s of their greatest pursuits. Extra environment friendly crawling not solely offers them entry to raised content material to energy their outcomes, however it additionally helps the world’s ecosystem by lowering greenhouse gases.
A lot of the discuss has been round two APIs which might be aimed toward optimizing crawling.
The thought is slightly than search engine spiders deciding what to crawl, web sites can push related URLs on to the various search engines through the API to set off a crawl.
In idea, this not solely lets you get your newest content material listed sooner, but additionally affords an avenue to successfully take away previous URLs, which is one thing that’s at the moment not well-supported by serps.
Non-Google Assist From IndexNow
The primary API is IndexNow. That is supported by Bing, Yandex, and Seznam, however importantly not Google. It is usually built-in into many Website positioning instruments, CRMs & CDNs, probably lowering the event effort wanted to leverage IndexNow.
This will seem to be a fast win for Website positioning, however be cautious.
Does a good portion of your audience use the various search engines supported by IndexNow? If not, triggering crawls from their bots could also be of restricted worth.
However extra importantly, assess what integrating on IndexNow does to server weight vs. crawl efficacy rating enchancment for these serps. It could be that the prices usually are not well worth the profit.
Google Assist From The Indexing API
The second is the Google Indexing API. Google has repeatedly acknowledged that the API can solely be used to crawl pages with both jobposting or broadcast occasion markup. And plenty of have examined this and proved this assertion to be false.
By submitting non-compliant URLs to the Google Indexing API you will note a major enhance in crawling. However that is the proper case for why “crawl funds optimization” and basing selections on the quantity of crawling is misconceived.
As a result of for non-compliant URLs, submission has no affect on indexing. And if you cease to consider it, this makes good sense.
You’re solely submitting a URL. Google will crawl the web page rapidly to see if it has the required structured information.
In that case, then it is going to expedite indexing. If not, it received’t. Google will ignore it.
So, calling the API for non-compliant pages does nothing besides add pointless load in your server and wastes growth sources for no achieve.
Google Assist Inside Google Search Console
The opposite means by which Google helps crawling is guide submission in Google Search Console.
Most URLs which might be submitted on this method shall be crawled and have their indexing standing modified inside an hour. However there’s a quota restrict of 10 URLs inside 24 hours, so the apparent subject with this tactic is scale.
Nevertheless, this doesn’t imply disregarding it.
You may automate the submission of URLs you see as a precedence through scripting that mimics consumer actions to hurry up crawling and indexing for these choose few.
Lastly, for anybody who hopes clicking the ‘Validate repair’ button on ‘found at the moment not listed’ exclusions will set off crawling, in my testing so far, this has finished nothing to expedite crawling.
So if serps is not going to considerably assist us, how can we assist ourselves?
How To Obtain Environment friendly Web site Crawling
There are 5 techniques that may make a distinction to crawl efficacy.
1. Guarantee A Quick, Wholesome Server Response
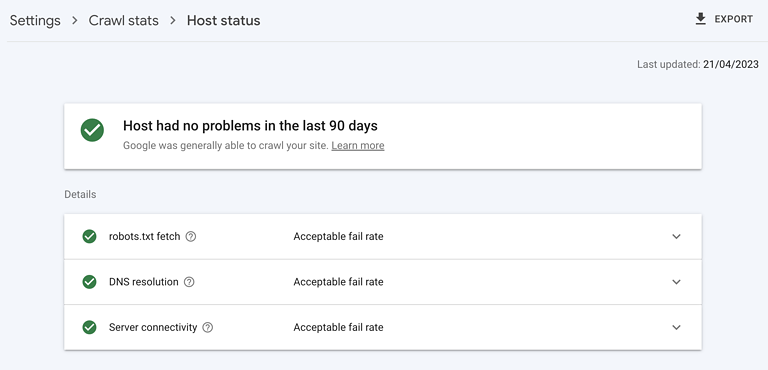 Screenshot from Google Search Console, Could 2023
Screenshot from Google Search Console, Could 2023A extremely performant server is crucial. It should be capable of deal with the quantity of crawling Googlebot desires to do with none damaging affect on server response time or erroring out.
Test your web site host standing is inexperienced in Google Search Console, that 5xx errors are beneath 1%, and server response occasions development beneath 300 milliseconds.
2. Take away Worthless Content material
When a good portion of a web site’s content material is low high quality, outdated, or duplicated, it diverts crawlers from visiting new or not too long ago up to date content material in addition to contributes to index bloat.
The quickest technique to begin cleansing up is to verify the Google Search Console pages report for the exclusion ‘Crawled – at the moment not listed.’
Within the offered pattern, search for folder patterns or different subject indicators. For these you discover, repair it by merging related content material with a 301 redirect or deleting content material with a 404 as applicable.
3. Instruct Googlebot What Not To Crawl
Whereas rel=canonical hyperlinks and noindex tags are efficient at protecting the Google index of your web site clear, they price you in crawling.
Whereas generally that is mandatory, think about if such pages should be crawled within the first place. If not, cease Google on the crawling stage with a robotic.txt disallow.
Discover situations the place blocking the crawler could also be higher than giving indexing directions by trying within the Google Search Console protection report for exclusions from canonicals or noindex tags.
Additionally, overview the pattern of ‘Listed, not submitted in sitemap’ and ‘Found – at the moment not listed’ URLs in Google Search Console. Discover and block non-Website positioning related routes akin to:
- Parameter pages, akin to ?type=oldest.
- Purposeful pages, akin to “buying cart.”
- Infinite areas, akin to these created by calendar pages.
- Unimportant photos, scripts, or fashion information.
- API URLs.
You also needs to think about how your pagination technique is impacting crawling.
4. Instruct Googlebot On What To Crawl And When
An optimized XML sitemap is an efficient device to information Googlebot towards Website positioning-relevant URLs.
Optimized signifies that it dynamically updates with minimal delay and consists of the final modification date and time to tell serps when the web page final was considerably modified and if it needs to be recrawled.
5. Assist Crawling By Inner Hyperlinks
We all know crawling can solely happen by way of hyperlinks. XML sitemaps are an awesome place to start out; exterior hyperlinks are highly effective however difficult to construct in bulk at high quality.
Inner hyperlinks, however, are comparatively straightforward to scale and have important constructive impacts on crawl efficacy.
Focus particular consideration on cell sitewide navigation, breadcrumbs, fast filters, and associated content material hyperlinks – guaranteeing none are dependent upon Javascript.
Optimize Net Crawling
I hope you agree: web site crawling is prime to Website positioning.
And now you will have an actual KPI in crawl efficacy to measure optimizations – so you may take your natural efficiency to the following stage.
Extra sources:
Featured Picture: BestForBest/Shutterstock