

{kind=link}
Robots.txt simply turned 30 – cue the existential disaster! Like many hitting the massive 3-0, it’s questioning if it’s nonetheless related in in the present day’s world of AI and superior search algorithms.
Spoiler alert: It undoubtedly is!
Let’s check out how this file nonetheless performs a key position in managing how search engines like google and yahoo crawl your website, how one can leverage it accurately, and customary pitfalls to keep away from.
What Is A Robots.txt File?
A robots.txt file supplies crawlers like Googlebot and Bingbot with tips for crawling your website. Like a map or listing on the entrance of a museum, it acts as a set of directions on the entrance of the web site, together with particulars on:
- What crawlers are/aren’t allowed to enter?
- Any restricted areas (pages) that shouldn’t be crawled.
- Precedence pages to crawl – through the XML sitemap declaration.
Its main position is to handle crawler entry to sure areas of an internet site by specifying which elements of the location are “off-limits.” This helps make sure that crawlers concentrate on probably the most related content material somewhat than losing the crawl funds on low-value content material.
Whereas a robots.txt guides crawlers, it’s essential to notice that not all bots observe its directions, particularly malicious ones. However for many legit search engines like google and yahoo, adhering to the robots.txt directives is customary observe.
What Is Included In A Robots.txt File?
Robots.txt information encompass strains of directives for search engine crawlers and different bots.
Legitimate strains in a robots.txt file encompass a area, a colon, and a worth.
Robots.txt information additionally generally embrace clean strains to enhance readability and feedback to assist web site house owners maintain monitor of directives.
To get a greater understanding of what’s sometimes included in a robots.txt file and the way totally different websites leverage it, I checked out robots.txt information for 60 domains with a excessive share of voice throughout well being, monetary providers, retail, and high-tech.
Excluding feedback and clean strains, the common variety of strains throughout 60 robots.txt information was 152.
Giant publishers and aggregators, comparable to lodges.com, forbes.com, and nytimes.com, sometimes had longer information, whereas hospitals like pennmedicine.org and hopkinsmedicine.com sometimes had shorter information. Retail website’s robots.txt information sometimes fall near the common of 152.
All websites analyzed embrace the fields user-agent and disallow inside their robots.txt information, and 77% of web sites included a sitemap declaration with the sphere sitemap.
Fields leveraged much less often have been enable (utilized by 60% of web sites) and crawl-delay (utilized by 20%) of web sites.
| Area | % of Websites Leveraging |
user-agent |
100% |
disallow |
100% |
sitemap |
77% |
enable |
60% |
crawl-delay |
20% |
Robots.txt Syntax
Now that we’ve lined what forms of fields are sometimes included in a robots.txt, we are able to dive deeper into what each means and how one can use it.
For extra data on robots.txt syntax and the way it’s interpreted by Google, take a look at Google’s robots.txt documentation.
Consumer-Agent
The user-agent area specifies what crawler the directives (disallow, enable) apply to. You need to use the user-agent area to create guidelines that apply to particular bots/crawlers or use a wild card to point guidelines that apply to all crawlers.
For instance, the under syntax signifies that any of the next directives solely apply to Googlebot.
user-agent: Googlebot
If you wish to create guidelines that apply to all crawlers, you need to use a wildcard as a substitute of naming a particular crawler.
user-agent: *
You possibly can embrace a number of user-agent fields inside your robots.txt to supply particular guidelines for various crawlers or teams of crawlers, for instance:
user-agent: *
#Guidelines right here would apply to all crawlers
user-agent: Googlebot
#Guidelines right here would solely apply to Googlebot
user-agent: otherbot1
user-agent: otherbot2
user-agent: otherbot3
#Guidelines right here would apply to otherbot1, otherbot2, and otherbot3
Disallow And Permit
The disallow area specifies paths that designated crawlers shouldn’t entry. The enable area specifies paths that designated crawlers can entry.
As a result of Googlebot and different crawlers will assume they will entry any URLs that aren’t particularly disallowed, many websites maintain it easy and solely specify what paths shouldn’t be accessed utilizing the disallow area.
For instance, the under syntax would inform all crawlers to not entry URLs matching the trail /do-not-enter.
user-agent: *
disallow: /do-not-enter
#All crawlers are blocked from crawling pages with the trail /do-not-enter
For those who’re utilizing each enable and disallow fields inside your robots.txt, be sure to learn the part on order of priority for guidelines in Google’s documentation.
Typically, within the case of conflicting guidelines, Google will use the extra particular rule.
For instance, within the under case, Google received’t crawl pages with the trail/do-not-enter as a result of the disallow rule is extra particular than the enable rule.
user-agent: *
enable: /
disallow: /do-not-enter
If neither rule is extra particular, Google will default to utilizing the much less restrictive rule.
Within the occasion under, Google would crawl pages with the trail/do-not-enter as a result of the enable rule is much less restrictive than the disallow rule.
user-agent: *
enable: /do-not-enter
disallow: /do-not-enter
Be aware that if there isn’t any path specified for the enable or disallow fields, the rule can be ignored.
user-agent: *
disallow:
That is very totally different from solely together with a ahead slash (/) as the worth for the disallow area, which might match the foundation area and any lower-level URL (translation: each web page in your website).
If you need your website to indicate up in search outcomes, ensure you don’t have the next code. It is going to block all search engines like google and yahoo from crawling all pages in your website.
user-agent: *
disallow: /
This might sound apparent, however consider me, I’ve seen it occur.
URL Paths
URL paths are the portion of the URL after the protocol, subdomain, and area starting with a ahead slash (/). For the instance URL https://www.instance.com/guides/technical/robots-txt, the trail could be /guides/technical/robots-txt.
 Picture from writer, November 2024
Picture from writer, November 2024URL paths are case-sensitive, so be sure you double-check that the usage of capitals and decrease circumstances within the robotic.txt aligns with the supposed URL path.
Particular Characters
Google, Bing, and different main search engines like google and yahoo additionally assist a restricted variety of particular characters to assist match URL paths.
A particular character is a logo that has a singular perform or that means as a substitute of simply representing an everyday letter or quantity. Particular characters supported by Google in robots.txt are:
- Asterisk (*) – matches 0 or extra cases of any character.
- Greenback signal ($) – designates the tip of the URL.
As an instance how these particular characters work, assume we’ve a small website with the next URLs:
- https://www.instance.com/
- https://www.instance.com/search
- https://www.instance.com/guides
- https://www.instance.com/guides/technical
- https://www.instance.com/guides/technical/robots-txt
- https://www.instance.com/guides/technical/robots-txt.pdf
- https://www.instance.com/guides/technical/xml-sitemaps
- https://www.instance.com/guides/technical/xml-sitemaps.pdf
- https://www.instance.com/guides/content material
- https://www.instance.com/guides/content material/on-page-optimization
- https://www.instance.com/guides/content material/on-page-optimization.pdf
Instance State of affairs 1: Block Web site Search Outcomes
A standard use of robots.txt is to dam inner website search outcomes, as these pages sometimes aren’t invaluable for natural search outcomes.
For this instance, assume when customers conduct a search on https://www.instance.com/search, their question is appended to the URL.
If a person searched “xml sitemap information,” the brand new URL for the search outcomes web page could be https://www.instance.com/search?search-query=xml-sitemap-guide.
If you specify a URL path within the robots.txt, it matches any URLs with that path, not simply the precise URL. So, to dam each the URLs above, utilizing a wildcard isn’t vital.
The next rule would match each https://www.instance.com/search and https://www.instance.com/search?search-query=xml-sitemap-guide.
user-agent: *
disallow: /search
#All crawlers are blocked from crawling pages with the trail /search
If a wildcard (*) have been added, the outcomes could be the identical.
user-agent: *
disallow: /search*
#All crawlers are blocked from crawling pages with the trail /search
Instance State of affairs 2: Block PDF information
In some circumstances, you might wish to use the robots.txt file to dam particular forms of information.
Think about the location determined to create PDF variations of every information to make it straightforward for customers to print. The result’s two URLs with precisely the identical content material, so the location proprietor might wish to block search engines like google and yahoo from crawling the PDF variations of every information.
On this case, utilizing a wildcard (*) could be useful to match the URLs the place the trail begins with /guides/ and ends with .pdf, however the characters in between fluctuate.
user-agent: *
disallow: /guides/*.pdf
#All crawlers are blocked from crawling pages with URL paths that comprise: /guides/, 0 or extra cases of any character, and .pdf
The above directive would forestall search engines like google and yahoo from crawling the next URLs:
- https://www.instance.com/guides/technical/robots-txt.pdf
- https://www.instance.com/guides/technical/xml-sitemaps.pdf
- https://www.instance.com/guides/content material/on-page-optimization.pdf
Instance State of affairs 3: Block Class Pages
For the final instance, assume the location created class pages for technical and content material guides to make it simpler for customers to browse content material sooner or later.
Nevertheless, for the reason that website solely has three guides revealed proper now, these pages aren’t offering a lot worth to customers or search engines like google and yahoo.
The positioning proprietor might wish to quickly forestall search engines like google and yahoo from crawling the class web page solely (e.g., https://www.instance.com/guides/technical), not the guides inside the class (e.g., https://www.instance.com/guides/technical/robots-txt).
To perform this, we are able to leverage “$” to designate the tip of the URL path.
user-agent: *
disallow: /guides/technical$
disallow: /guides/content material$
#All crawlers are blocked from crawling pages with URL paths that finish with /guides/technical and /guides/content material
The above syntax would forestall the next URLs from being crawled:
- https://www.instance.com/guides/technical
- https://www.instance.com/guides/content material
Whereas permitting search engines like google and yahoo to crawl:
- https://www.instance.com/guides/technical/robots-txt
- https://www.instance.com/guides/content material/on-page-optimization
Sitemap
The sitemap area is used to supply search engines like google and yahoo with a hyperlink to a number of XML sitemaps.
Whereas not required, it’s a finest observe to incorporate XML sitemaps inside the robots.txt file to supply search engines like google and yahoo with an inventory of precedence URLs to crawl.
The worth of the sitemap area must be an absolute URL (e.g., https://www.instance.com/sitemap.xml), not a relative URL (e.g., /sitemap.xml). When you have a number of XML sitemaps, you’ll be able to embrace a number of sitemap fields.
Instance robots.txt with a single XML sitemap:
user-agent: *
disallow: /do-not-enter
sitemap: https://www.instance.com/sitemap.xml
Instance robots.txt with a number of XML sitemaps:
user-agent: *
disallow: /do-not-enter
sitemap: https://www.instance.com/sitemap-1.xml
sitemap: https://www.instance.com/sitemap-2.xml
sitemap: https://www.instance.com/sitemap-3.xml
Crawl-Delay
As talked about above, 20% of web sites additionally embrace the crawl-delay area inside their robots.txt file.
The crawl delay area tells bots how briskly they will crawl the location and is usually used to decelerate crawling to keep away from overloading servers.
The worth for crawl-delay is the variety of seconds crawlers ought to wait to request a brand new web page. The under rule would inform the required crawler to attend 5 seconds after every request earlier than requesting one other URL.
user-agent: FastCrawlingBot
crawl-delay: 5
Google has said that it doesn’t assist the crawl-delay area, and it is going to be ignored.
Different main search engines like google and yahoo like Bing and Yahoo respect crawl-delay directives for his or her internet crawlers.
| Search Engine | Main user-agent for search | Respects crawl-delay? |
| Googlebot | No | |
| Bing | Bingbot | Sure |
| Yahoo | Slurp | Sure |
| Yandex | YandexBot | Sure |
| Baidu | Baiduspider | No |
Websites mostly embrace crawl-delay directives for all person brokers (utilizing user-agent: *), search engine crawlers talked about above that respect crawl-delay, and crawlers for website positioning instruments like Ahrefbot and SemrushBot.
The variety of seconds crawlers have been instructed to attend earlier than requesting one other URL ranged from one second to twenty seconds, however crawl-delay values of 5 seconds and 10 seconds have been the commonest throughout the 60 websites analyzed.
Testing Robots.txt Information
Any time you’re creating or updating a robots.txt file, be sure to check directives, syntax, and construction earlier than publishing.
This robots.txt Validator and Testing Software makes this straightforward to do (thanks, Max Prin!).
To check a reside robots.txt file, merely:
- Add the URL you wish to take a look at.
- Choose your person agent.
- Select “reside.”
- Click on “take a look at.”
The under instance exhibits that Googlebot smartphone is allowed to crawl the examined URL.
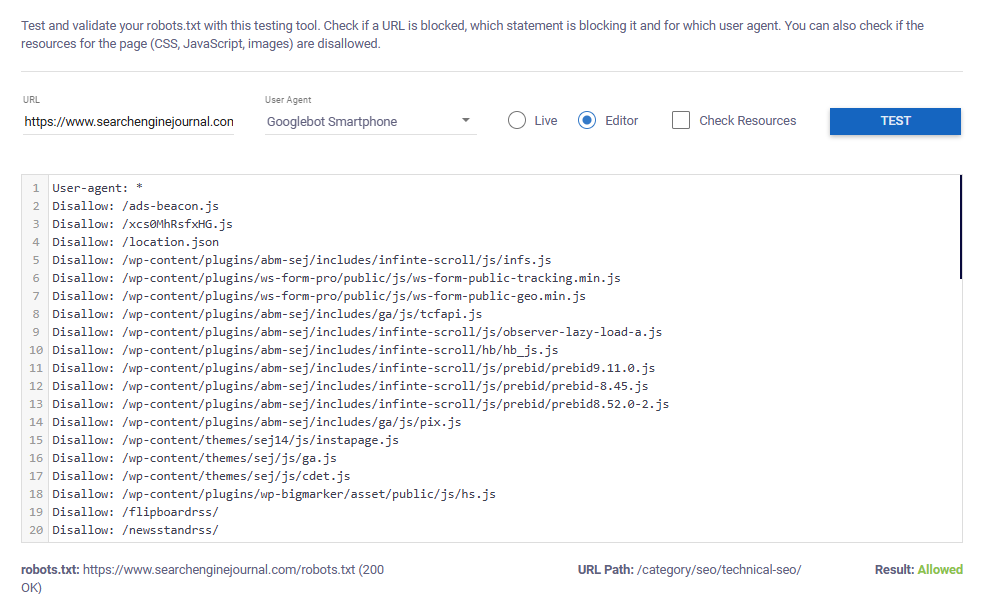 Picture from writer, November 2024
Picture from writer, November 2024If the examined URL is blocked, the device will spotlight the particular rule that forestalls the chosen person agent from crawling it.
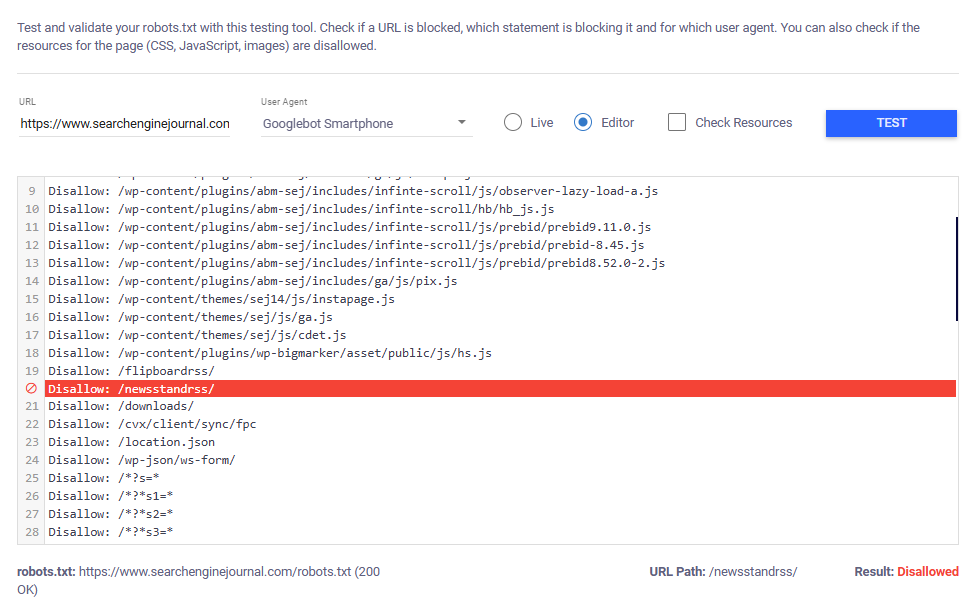 Picture from writer, November 2024
Picture from writer, November 2024To check new guidelines earlier than they’re revealed, change to “Editor” and paste your guidelines into the textual content field earlier than testing.
Widespread Makes use of Of A Robots.txt File
Whereas what’s included in a robots.txt file varies tremendously by web site, analyzing 60 robots.txt information revealed some commonalities in how it’s leveraged and what forms of content material site owners generally block search engines like google and yahoo from crawling.
Stopping Search Engines From Crawling Low-Worth Content material
Many web sites, particularly giant ones like ecommerce or content-heavy platforms, typically generate “low-value pages” as a byproduct of options designed to enhance the person expertise.
For instance, inner search pages and faceted navigation choices (filters and types) assist customers discover what they’re in search of shortly and simply.
Whereas these options are important for usability, they may end up in duplicate or low-value URLs that aren’t invaluable for search.
The robots.txt is usually leveraged to dam these low-value pages from being crawled.
Widespread forms of content material blocked through the robots.txt embrace:
- Parameterized URLs: URLs with monitoring parameters, session IDs, or different dynamic variables are blocked as a result of they typically result in the identical content material, which might create duplicate content material points and waste the crawl funds. Blocking these URLs ensures search engines like google and yahoo solely index the first, clear URL.
- Filters and types: Blocking filter and kind URLs (e.g., product pages sorted by value or filtered by class) helps keep away from indexing a number of variations of the identical web page. This reduces the danger of duplicate content material and retains search engines like google and yahoo centered on a very powerful model of the web page.
- Inner search outcomes: Inner search consequence pages are sometimes blocked as a result of they generate content material that doesn’t supply distinctive worth. If a person’s search question is injected into the URL, web page content material, and meta components, websites would possibly even danger some inappropriate, user-generated content material getting crawled and listed (see the pattern screenshot on this publish by Matt Tutt). Blocking them prevents this low-quality – and probably inappropriate – content material from showing in search.
- Consumer profiles: Profile pages could also be blocked to guard privateness, scale back the crawling of low-value pages, or guarantee concentrate on extra essential content material, like product pages or weblog posts.
- Testing, staging, or growth environments: Staging, growth, or take a look at environments are sometimes blocked to make sure that personal content material shouldn’t be crawled by search engines like google and yahoo.
- Marketing campaign sub-folders: Touchdown pages created for paid media campaigns are sometimes blocked after they aren’t related to a broader search viewers (i.e., a junk mail touchdown web page that prompts customers to enter a redemption code).
- Checkout and affirmation pages: Checkout pages are blocked to stop customers from touchdown on them instantly via search engines like google and yahoo, enhancing person expertise and defending delicate data through the transaction course of.
- Consumer-generated and sponsored content material: Sponsored content material or user-generated content material created through opinions, questions, feedback, and so on., are sometimes blocked from being crawled by search engines like google and yahoo.
- Media information (photographs, movies): Media information are typically blocked from being crawled to preserve bandwidth and scale back the visibility of proprietary content material in search engines like google and yahoo. It ensures that solely related internet pages, not standalone information, seem in search outcomes.
- APIs: APIs are sometimes blocked to stop them from being crawled or listed as a result of they’re designed for machine-to-machine communication, not for end-user search outcomes. Blocking APIs protects their utilization and reduces pointless server load from bots making an attempt to entry them.
Blocking “Dangerous” Bots
Dangerous bots are internet crawlers that interact in undesirable or malicious actions comparable to scraping content material and, in excessive circumstances, in search of vulnerabilities to steal delicate data.
Different bots with none malicious intent should still be thought-about “unhealthy” in the event that they flood web sites with too many requests, overloading servers.
Moreover, site owners might merely not need sure crawlers accessing their website as a result of they don’t stand to realize something from it.
For instance, you might select to dam Baidu for those who don’t serve prospects in China and don’t wish to danger requests from Baidu impacting your server.
Although a few of these “unhealthy” bots might disregard the directions outlined in a robots.txt file, web sites nonetheless generally embrace guidelines to disallow them.
Out of the 60 robots.txt information analyzed, 100% disallowed no less than one person agent from accessing all content material on the location (through the disallow: /).
Blocking AI Crawlers
Throughout websites analyzed, probably the most blocked crawler was GPTBot, with 23% of web sites blocking GPTBot from crawling any content material on the location.
Orginality.ai’s reside dashboard that tracks how most of the high 1,000 web sites are blocking particular AI internet crawlers discovered related outcomes, with 27% of the highest 1,000 websites blocking GPTBot as of November 2024.
Causes for blocking AI internet crawlers might fluctuate – from issues over knowledge management and privateness to easily not wanting your knowledge utilized in AI coaching fashions with out compensation.
The choice on whether or not or to not block AI bots through the robots.txt must be evaluated on a case-by-case foundation.
For those who don’t need your website’s content material for use to coach AI but in addition wish to maximize visibility, you’re in luck. OpenAI is clear on the way it makes use of GPTBot and different internet crawlers.
At a minimal, websites ought to contemplate permitting OAI-SearchBot, which is used to function and hyperlink to web sites within the SearchGPT – ChatGPT’s lately launched real-time search function.
Blocking OAI-SearchBot is much much less widespread than blocking GPTBot, with solely 2.9% of the highest 1,000 websites blocking the SearchGPT-focused crawler.
Getting Inventive
Along with being an essential device in controlling how internet crawlers entry your website, the robots.txt file may also be a chance for websites to indicate their “artistic” aspect.
Whereas sifting via information from over 60 websites, I additionally got here throughout some pleasant surprises, just like the playful illustrations hidden within the feedback on Marriott and Cloudflare’s robots.txt information.
 Screenshot of marriot.com/robots.txt, November 2024
Screenshot of marriot.com/robots.txt, November 2024 Screenshot of cloudflare.com/robots.txt, November 2024
Screenshot of cloudflare.com/robots.txt, November 2024A number of firms are even turning these information into distinctive recruitment instruments.
TripAdvisor’s robots.txt doubles as a job posting with a intelligent message included within the feedback:
“For those who’re sniffing round this file, and also you’re not a robotic, we’re trying to meet curious of us comparable to your self…
Run – don’t crawl – to use to affix TripAdvisor’s elite website positioning workforce[.]”
For those who’re in search of a brand new profession alternative, you would possibly wish to contemplate searching robots.txt information along with LinkedIn.
How To Audit Robots.txt
Auditing your Robots.txt file is a vital a part of most technical website positioning audits.
Conducting an intensive robots.txt audit ensures that your file is optimized to reinforce website visibility with out inadvertently limiting essential pages.
To audit your Robots.txt file:
- Crawl the location utilizing your most popular crawler. (I sometimes use Screaming Frog, however any internet crawler ought to do the trick.)
- Filter crawl for any pages flagged as “blocked by robots.txt.” In Screaming Frog, yow will discover this data by going to the response codes tab and filtering by “blocked by robots.txt.”
- Evaluate the checklist of URLs blocked by the robots.txt to find out whether or not they ought to be blocked. Check with the above checklist of widespread forms of content material blocked by robots.txt that can assist you decide whether or not the blocked URLs must be accessible to search engines like google and yahoo.
- Open your robots.txt file and conduct further checks to ensure your robots.txt file follows website positioning finest practices (and avoids widespread pitfalls) detailed under.
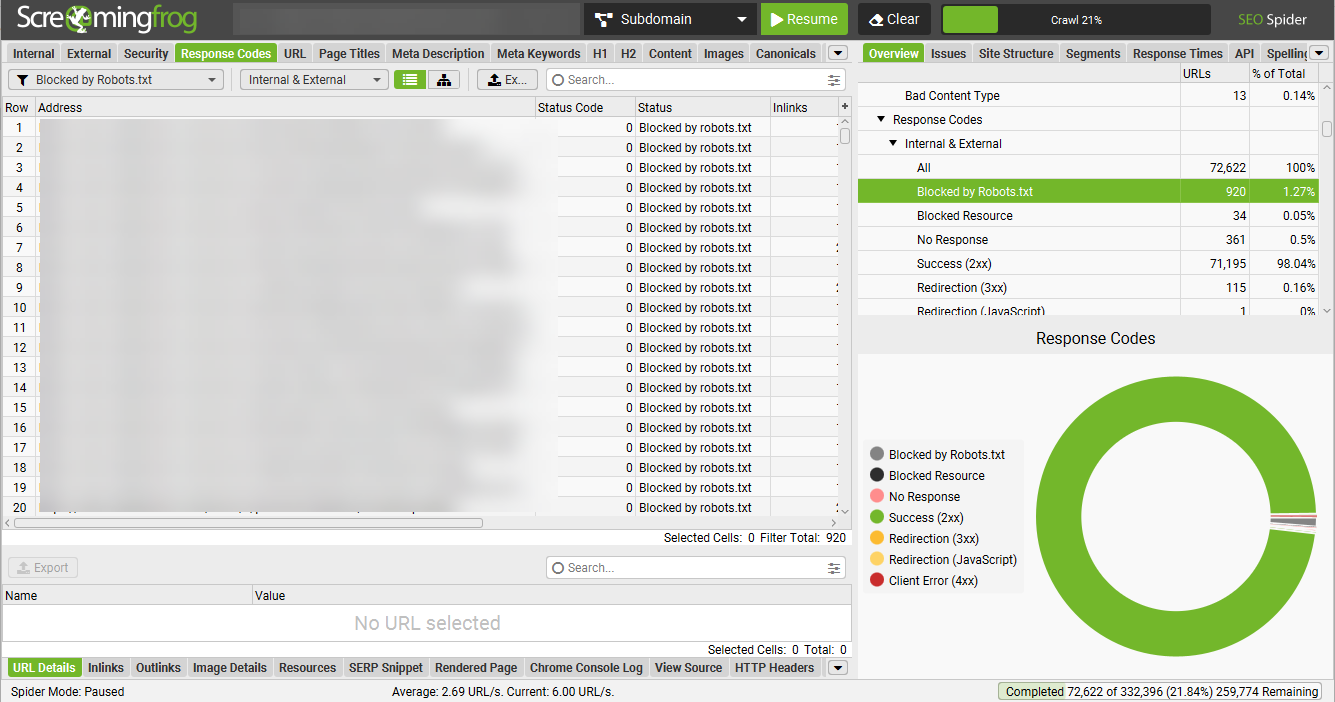 Picture from writer, November 2024
Picture from writer, November 2024Robots.txt Finest Practices (And Pitfalls To Keep away from)
The robots.txt is a robust device when used successfully, however there are some widespread pitfalls to avoid for those who don’t wish to hurt the location unintentionally.
The next finest practices will assist set your self up for achievement and keep away from unintentionally blocking search engines like google and yahoo from crawling essential content material:
- Create a robots.txt file for every subdomain. Every subdomain in your website (e.g., weblog.yoursite.com, store.yoursite.com) ought to have its personal robots.txt file to handle crawling guidelines particular to that subdomain. Engines like google deal with subdomains as separate websites, so a singular file ensures correct management over what content material is crawled or listed.
- Don’t block essential pages on the location. Ensure precedence content material, comparable to product and repair pages, contact data, and weblog content material, are accessible to search engines like google and yahoo. Moreover, ensure that blocked pages aren’t stopping search engines like google and yahoo from accessing hyperlinks to content material you wish to be crawled and listed.
- Don’t block important assets. Blocking JavaScript (JS), CSS, or picture information can forestall search engines like google and yahoo from rendering your website accurately. Be certain that essential assets required for a correct show of the location should not disallowed.
- Embody a sitemap reference. At all times embrace a reference to your sitemap within the robots.txt file. This makes it simpler for search engines like google and yahoo to find and crawl your essential pages extra effectively.
- Don’t solely enable particular bots to entry your website. For those who disallow all bots from crawling your website, aside from particular search engines like google and yahoo like Googlebot and Bingbot, you might unintentionally block bots that would profit your website. Instance bots embrace:
- FacebookExtenalHit – used to get open graph protocol.
- GooglebotNews – used for the Information tab in Google Search and the Google Information app.
- AdsBot-Google – used to test webpage advert high quality.
- Don’t block URLs that you really want faraway from the index. Blocking a URL in robots.txt solely prevents search engines like google and yahoo from crawling it, not from indexing it if the URL is already identified. To take away pages from the index, use different strategies just like the “noindex” tag or URL removing instruments, making certain they’re correctly excluded from search outcomes.
- Don’t block Google and different main search engines like google and yahoo from crawling your total website. Simply don’t do it.
TL;DR
- A robots.txt file guides search engine crawlers on which areas of an internet site to entry or keep away from, optimizing crawl effectivity by specializing in high-value pages.
- Key fields embrace “Consumer-agent” to specify the goal crawler, “Disallow” for restricted areas, and “Sitemap” for precedence pages. The file can even embrace directives like “Permit” and “Crawl-delay.”
- Web sites generally leverage robots.txt to dam inner search outcomes, low-value pages (e.g., filters, type choices), or delicate areas like checkout pages and APIs.
- An growing variety of web sites are blocking AI crawlers like GPTBot, although this won’t be the very best technique for websites trying to achieve site visitors from further sources. To maximise website visibility, contemplate permitting OAI-SearchBot at a minimal.
- To set your website up for achievement, guarantee every subdomain has its personal robots.txt file, take a look at directives earlier than publishing, embrace an XML sitemap declaration, and keep away from by chance blocking key content material.
Extra assets:
Featured Picture: Se_vector/Shutterstock