

{kind=link}
Your web site possible suffers from a minimum of some content material cannibalization, and also you may not even notice it.
Cannibalization hurts natural visitors and income: The impression can stretch from key pages not rating to algorithm points attributable to low area high quality.
Nonetheless, cannibalization is hard to detect, can change over time, and exists on a spectrum.
It’s the “microplastics of Search engine marketing.”
On this Memo, I’ll present you:
- The right way to establish and repair content material cannibalization reliably.
- The right way to automate content material cannibalization detection.
- An automatic workflow you’ll be able to check out proper now: The Cannibalization Detector, my new key phrase cannibalization software.
I might have by no means carried out this with out Nicole Guercia from AirOps. I’ve designed the idea and stress-tested the automated workflow, however Nicole constructed the entire thing.
How To Suppose About Content material Cannibalization The Proper Method
Earlier than leaping into the workflow, we should make clear just a few guiding ideas about content material cannibalization which are usually misunderstood.
The most important false impression about cannibalization is that it occurs on the key phrase stage.
It’s truly occurring on the person intent stage.
All of us have to cease fascinated by this idea as key phrase cannibalization and as a substitute as content material cannibalization based mostly on person intent.
With this in thoughts, cannibalization…
- Is a transferring goal: When Google updates its understanding of intent throughout a core replace, all of the sudden two pages can compete with one another that beforehand didn’t.
- Exists on a spectrum: A web page can compete with one other web page or a number of pages, with an intent overlap from 10% to 100%. It’s onerous to say precisely how a lot overlap is okay with out taking a look at outcomes and context.
- Doesn’t cease at rankings: On the lookout for two pages which are getting a “substantial” quantity of impressions or rankings for a similar key phrase(s) will help you notice cannibalization, however it’s not a really correct technique. It’s not sufficient proof.
- Wants common check-ups: It’s essential to examine your web site for cannibalization frequently and deal with your content material library as a “residing” ecosystem.
- Could be sneaky: Many instances usually are not clear-cut. For instance, worldwide content material cannibalization is just not apparent. A /en listing to deal with all English-speaking international locations can compete with a /en-us listing for the U.S. market.
Various kinds of websites have basically completely different weaknesses for cannibalization.
My mannequin for web site varieties is the integrator vs. aggregator mannequin. On-line retailers and different marketplaces face basically completely different instances of cannibalization than SaaS or D2C corporations.
Integrators cannibalize between pages. Aggregators cannibalize between web page varieties.
- With aggregators, cannibalization usually occurs when two web page varieties are too comparable. For instance, you’ll be able to have two web page varieties that would or couldn’t compete with one another: “factors of curiosity in {metropolis}” and “issues to do in {metropolis}”.
- With integrators, cannibalization usually occurs when corporations publish new content material with out upkeep and a plan for the present content material. An enormous a part of the difficulty is that it turns into tougher to maintain an summary of what you’ve got and what key phrases/intent it targets at a sure variety of articles (I discovered the linchpin to be round 250 articles).
How To Spot Content material Cannibalization
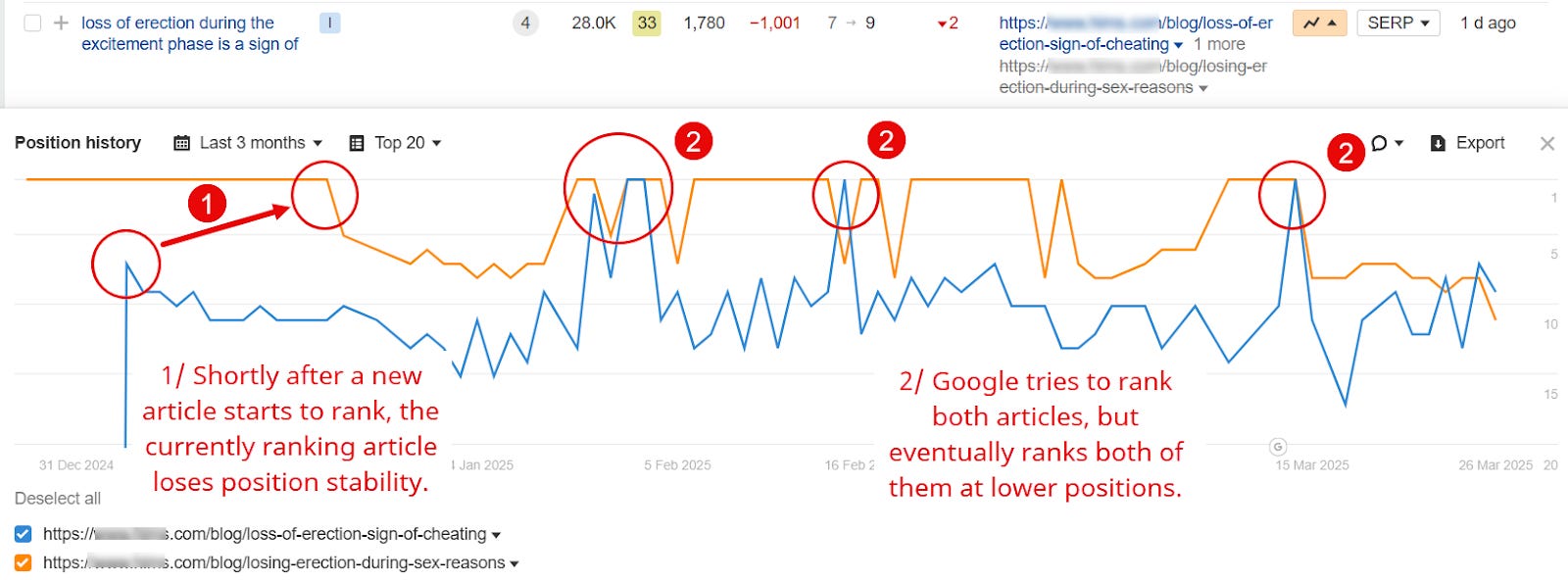 An instance of content material cannibalization (Picture Credit score: Kevin Indig)
An instance of content material cannibalization (Picture Credit score: Kevin Indig)Content material cannibalization can have a number of of the next signs:
- “URL flickering”: which means a minimum of two URLs alternate in rating for a number of key phrases.
- A web page loses visitors and/or rating positions after one other one goes reside.
- A brand new web page hits a rating plateau for its essential key phrase and can’t break into the highest 3 positions.
- Google doesn’t index a brand new web page or pages inside the similar web page sort.
- Actual duplicate titles seem in Google’s search index.
- Google experiences “crawled, not listed” or “found, not listed” for URLs that don’t have skinny content material or technical points.
Since Google doesn’t give us a transparent sign for cannibalization, one of the best ways to measure similarity between two or extra pages is cosine similarity between their tokenized embeddings (I do know, it’s a mouthful).
However that is what it means: Mainly, you examine how comparable two pages are by turning their textual content into numbers and seeing how intently these numbers level in the identical path.
Give it some thought like a chocolate cookie recipe:
- Tokenization = Break down every recipe (e.g., web page content material) into elements: flour, sugar, chocolate chips, and so on.
- Embeddings = Convert every ingredient into numbers, like how a lot of every ingredient is used and the way necessary every one is to the recipe’s identification.
- Cosine Similarity = Examine the recipes mathematically. This provides you a quantity between 0 and 1. A rating of 1 means the recipes are equivalent, whereas 0 means they’re fully completely different.
Comply with this course of to scan your web site and discover cannibalization candidates:
- Crawl: Scrape your web site with a software like Screaming Frog (optionally, exclude pages that don’t have any Search engine marketing function) to extract the URL and meta title of every web page
- Tokenization: Flip phrases in each the URL and title into items of phrases which are simpler to work with. These are your tokens.
- Embeddings: Flip the tokens into numbers to do “phrase math.”
- Similarity: Calculate the cosine similarity between all URLs and meta titles
Ideally, this offers you a shortlist of URLs and titles which are too comparable.
Within the subsequent step, you’ll be able to apply the next course of to ensure they really cannibalize one another:
- Extract content material: Clearly isolate the primary content material (exclude navigation, footer, adverts, and so on.). Perhaps clear up sure components, like cease phrases.
- Chunking or tokenization: Both cut up content material into significant chunks (sentences or paragraphs) or tokenize straight. I favor the latter.
- Embeddings: Embed the tokens.
- Entities: Extract named entities from the tokens and weigh them greater in embeddings. In essence, you examine which embeddings are “identified issues” and provides them extra energy in your evaluation.
- Aggregation of embeddings: Mixture token/chunk embeddings with a weighted averaging (eg, TF-IDF) or attention-weighted pooling.
- Cosine similarity: Calculate cosine similarity between ensuing embeddings.
You should utilize my app script for those who’d prefer to attempt it out in Google Sheets (however I’ve a greater various for you in a second).
About cosine similarity: It’s not excellent, however adequate.
Sure, you’ll be able to fine-tune embedding fashions for particular matters.
And sure, you should utilize superior embedding fashions like sentence transformers on prime, however this simplified course of is often enough. No have to make an astrophysics venture out of it.
How To Repair Cannibalization
When you’ve recognized cannibalization, you need to take motion.
However don’t overlook to regulate your long-term method to content material creation and governance. Should you don’t, all this work to search out and repair cannibalization goes to be a waste.
Fixing Cannibalization In The Brief Time period
The short-term motion you need to take is determined by the diploma of cannibalization and the way rapidly you’ll be able to act.
“Diploma” means how comparable the content material throughout two or extra pages is, expressed in cosine or content material similarity.
Although not a precise science, in my expertise, a cosine similarity greater than 0.7 is classed as “excessive”, whereas it’s “low” beneath a worth of 0.5.
 4 methods to repair cannibalization (Picture Credit score: Kevin Indig)
4 methods to repair cannibalization (Picture Credit score: Kevin Indig)What to do if the pages have a excessive diploma of similarity:
- Canonicalize or noindex the web page when cannibalization occurs attributable to technical points like parameter URLs, or if the cannibalizing web page is irrelevant for Search engine marketing, like paid touchdown pages. On this case, canonicalize the parameter URL to the non-parameter URL (or noindex the paid touchdown web page).
- Consolidate with one other web page when it’s not a technical difficulty. Consolidation means combining the content material and redirecting the URLs. I recommend taking the older web page and/or the worse-performing web page and redirecting to a brand new, higher web page. Then, switch any helpful content material to the brand new variant.
What to do if the pages have a low diploma of similarity:
- Noindex or take away (standing code: 410) if you don’t have the capability or skill to make content material modifications.
- Disambiguate the intent focus of the content material in case you have the capability, and if the overlap is just not too robust. In essence, you need to differentiate the components of the pages which are too comparable.
Fixing Cannibalization In The Lengthy Time period
It’s essential to take long-term motion to regulate your technique or manufacturing course of as a result of content material cannibalization is a symptom of an even bigger difficulty, not a root trigger.
(Except we’re speaking about Google altering its understanding of intent throughout a core algorithm replace, and that has nothing to do with you or your crew.)
Probably the most essential long-term modifications you want to make are:
- Create a content material roadmap: Search engine marketing Integrators ought to preserve a residing spreadsheet or database with all Search engine marketing-relevant URLs and their essential goal key phrases and intent to tighten editorial oversight. Whoever is in command of the content material roadmap wants to make sure there is no such thing as a overlap between articles and different web page varieties. Writers have to have a transparent goal intent for brand spanking new and present content material.
- Develop clear web site structure: The pendant of a content material map for Search engine marketing Aggregators is a web site structure map, which is solely an summary of various web page varieties and the intent they aim. It’s essential to underline the intent as you outline it with instance key phrases that you just confirm regularly (”Are we nonetheless rating nicely for these key phrases?”) to match it towards Google’s understanding and rivals.
The final query is: “How do I do know when content material cannibalization is fastened?”
The reply is when the signs talked about within the earlier chapter go away:
- Indexing points resolve.
- URL flickering goes away.
- No duplicate titles seem in Google’s search index.
- “Crawled, not listed” or “found, not listed” points lower.
- Rankings stabilize and break by a plateau (if the web page has no different obvious points).
And, after working with my shoppers beneath this guide framework for years, I made a decision it’s time to automate it.
Introducing: A Totally Automated Cannibalization Detector
Along with Nicole, I used AirOps to construct a totally automated AI workflow that goes by 37 steps to detect cannibalization inside minutes.
It performs an intensive evaluation of content material cannibalization by analyzing key phrase rankings, content material similarity, and historic information.
Beneath, I’ll break down crucial steps that it automates in your behalf:
1. Preliminary URL Processing
The workflow extracts and normalizes the area and model identify from the enter URL.
This foundational step establishes the goal web site’s identification and creates the baseline for all subsequent evaluation.
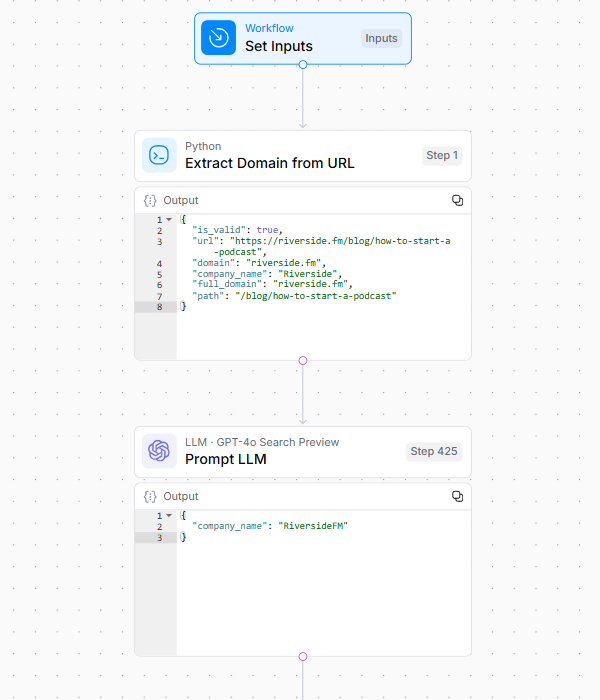 Picture Credit score: Kevin Indig
Picture Credit score: Kevin Indig2. Goal Content material Evaluation
To make sure that the system has high quality supply materials to investigate and examine towards rivals, Step 2 entails:
- Scraping the web page.
- Validating and analyzing the HTML construction for essential content material extraction.
- Cleansing the article content material and producing goal embeddings.
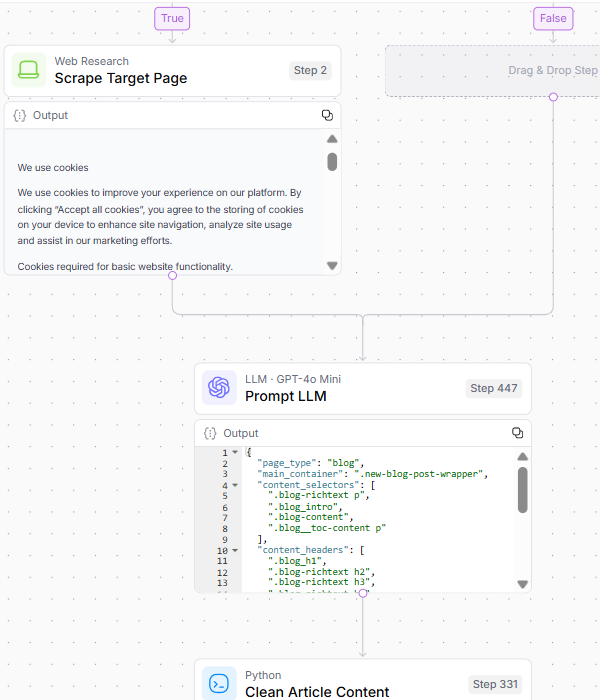 Picture Credit score: Kevin Indig
Picture Credit score: Kevin Indig3. Key phrase Evaluation
Step 3 reveals the goal URL’s search visibility and potential vulnerabilities by:
- Analyzing rating key phrases by Semrush information.
- Filtering branded versus non-branded phrases.
- Figuring out SERP overlap with competing URLs.
- Conducting historic rating evaluation.
- Figuring out web page worth based mostly on a number of metrics.
- Analyzing place differential modifications over time.
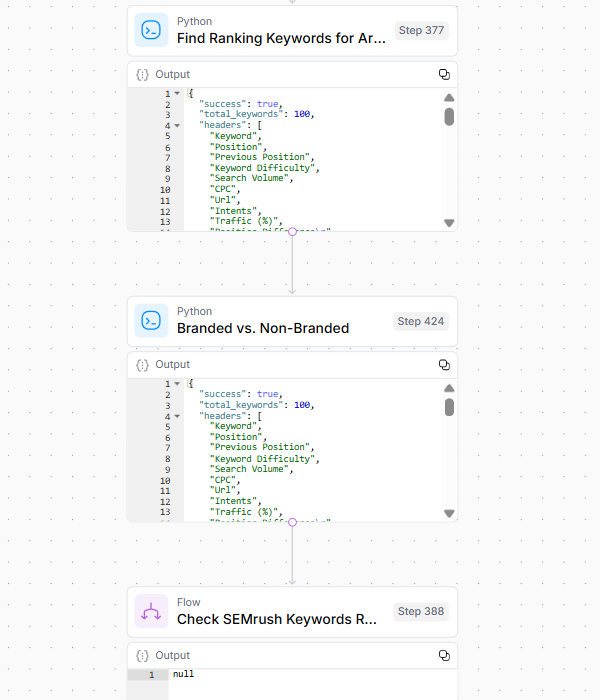 Picture Credit score: Kevin Indig
Picture Credit score: Kevin Indig4. Competing Content material Evaluation (Iteration Over Competing URLs)
Step 4 gathers extra context for cannibalization by iteratively processing every competing URL within the search outcomes by the earlier steps.
 Picture Credit score: Kevin Indig
Picture Credit score: Kevin Indig5. Ultimate Report Technology
Within the ultimate step, the workflow cleans up the info and generates an actionable report.
 Picture Credit score: Kevin Indig
Picture Credit score: Kevin IndigAttempt The Automated Content material Cannibalization Detector
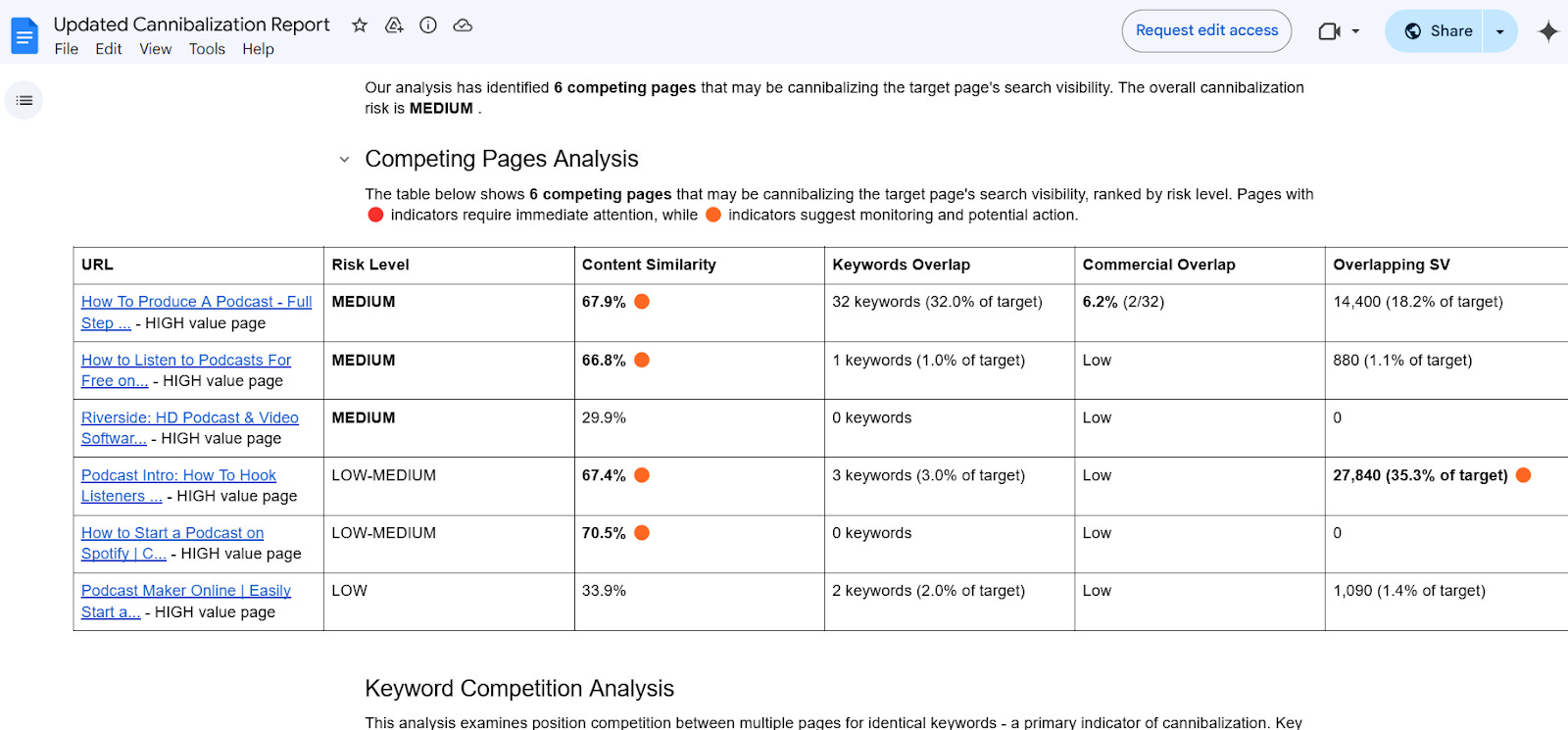 Picture Credit score: Kevin Indig
Picture Credit score: Kevin IndigAttempt the Cannibalization Detector and take a look at an instance report.
Just a few issues to notice:
- That is an early model. We’re planning to optimize and enhance it over time.
- The workflow can outing attributable to a excessive variety of requests. We deliberately restrict utilization in order to not get overwhelmed by API calls (they value cash). We’ll monitor utilization and would possibly quickly increase the restrict, which suggests in case your first try isn’t profitable, attempt once more in a couple of minutes. It would simply be a short lived spike in utilization.
- I’m an advisor to AirOps however was neither paid nor incentivized in another strategy to construct this workflow.
Please go away your suggestions within the feedback.
We’d love to listen to how we are able to take the Cannibalization Detector to the following stage!
Increase your expertise with Development Memo’s weekly knowledgeable insights. Subscribe without cost!
Featured Picture: Paulo Bobita/Search Engine Journal